Running Ollama with AutoGPT¶
Important: Ollama integration is only available when self-hosting the AutoGPT platform. It cannot be used with the cloud-hosted version.
Follow these steps to set up and run Ollama with the AutoGPT platform.
Prerequisites¶
- Make sure you have gone through and completed the AutoGPT Setup steps, if not please do so before continuing with this guide.
- Before starting, ensure you have Ollama installed on your machine.
Setup Steps¶
1. Launch Ollama¶
To properly set up Ollama for network access, choose one of these methods:
Method A: Using Ollama Desktop App (Recommended)
- Open the Ollama desktop application
- Go to Settings and toggle "Expose Ollama to the network"
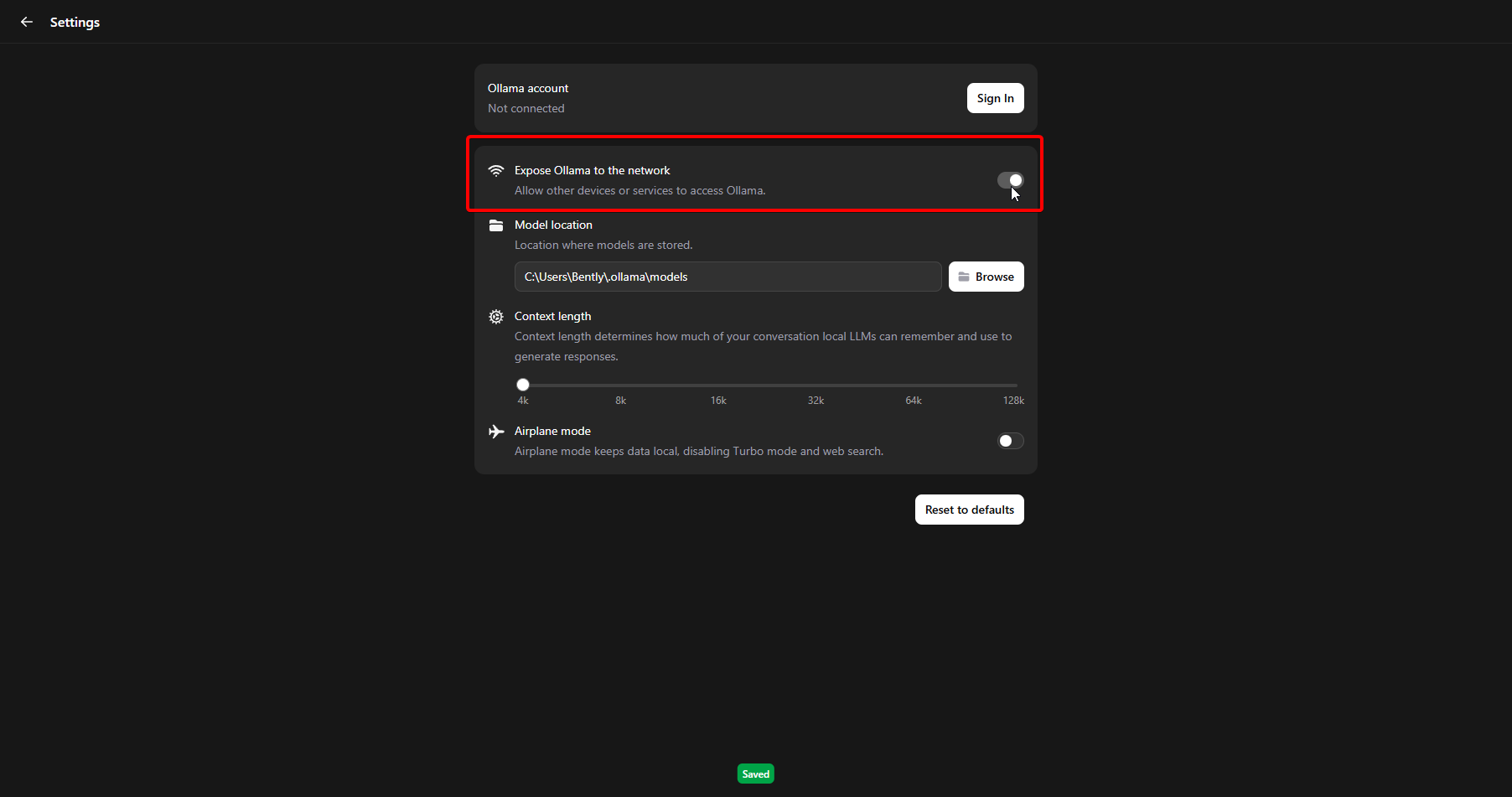
- Click on the model name field in the "New Chat" window
- Search for "llama3.2" (or your preferred model)
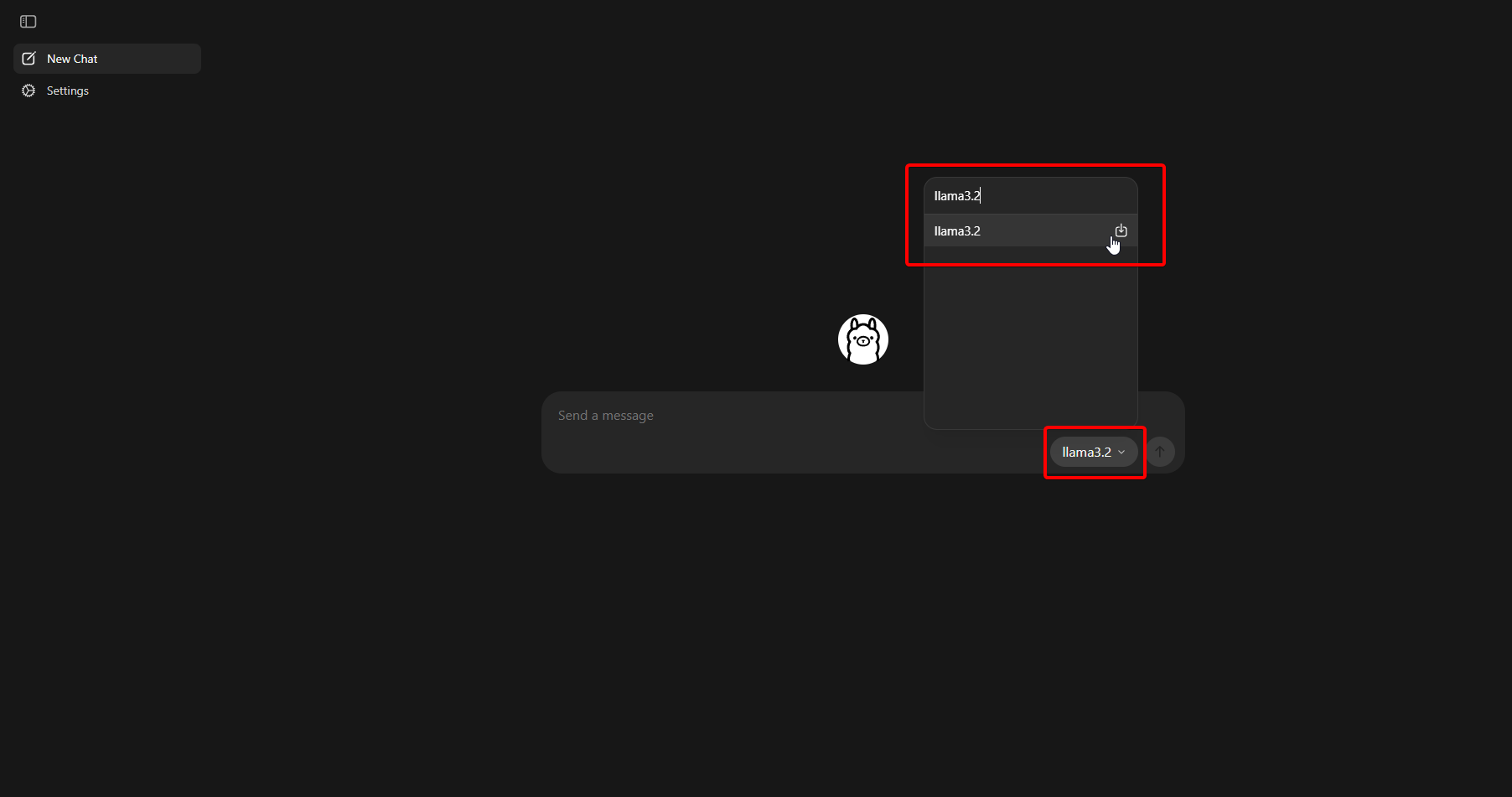
- Click on it to start the download and load the model to be used
Method B: Using Docker (Alternative)
If you prefer to run Ollama via Docker instead of the desktop app, you can use the official Ollama Docker image:
- Start Ollama container (choose based on your hardware):
CPU only:
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
With NVIDIA GPU (requires NVIDIA Container Toolkit):
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
With AMD GPU:
docker run -d --device /dev/kfd --device /dev/dri -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:rocm
Download your desired model:
docker exec -it ollama ollama run llama3.2
Note
The Docker method automatically exposes Ollama on 0.0.0.0:11434, making it accessible to AutoGPT. More models can be found on the Ollama library.
Method C: Using Ollama Via Command Line (Legacy)
For users still using the traditional CLI approach or older Ollama installations:
- Set the host environment variable:
Windows (Command Prompt):
set OLLAMA_HOST=0.0.0.0:11434
Linux/macOS (Terminal):
export OLLAMA_HOST=0.0.0.0:11434
-
Start the Ollama server:
ollama serve -
Open a new terminal/command window and download your desired model:
ollama pull llama3.2
Note
This will download the llama3.2 model. Keep the terminal with ollama serve running in the background throughout your session.
2. Start the AutoGPT Platform¶
Navigate to the autogpt_platform directory and start all services:
cd autogpt_platform
docker compose up -d --build
This command starts both the backend and frontend services. Once running, visit http://localhost:3000 to access the platform. After registering/logging in, navigate to the build page at http://localhost:3000/build.
3. Using Ollama with AutoGPT¶
Now that both Ollama and the AutoGPT platform are running, we can use Ollama with AutoGPT:
-
Add an AI Text Generator block to your workspace (it can work with any AI LLM block but for this example will be using the AI Text Generator block):
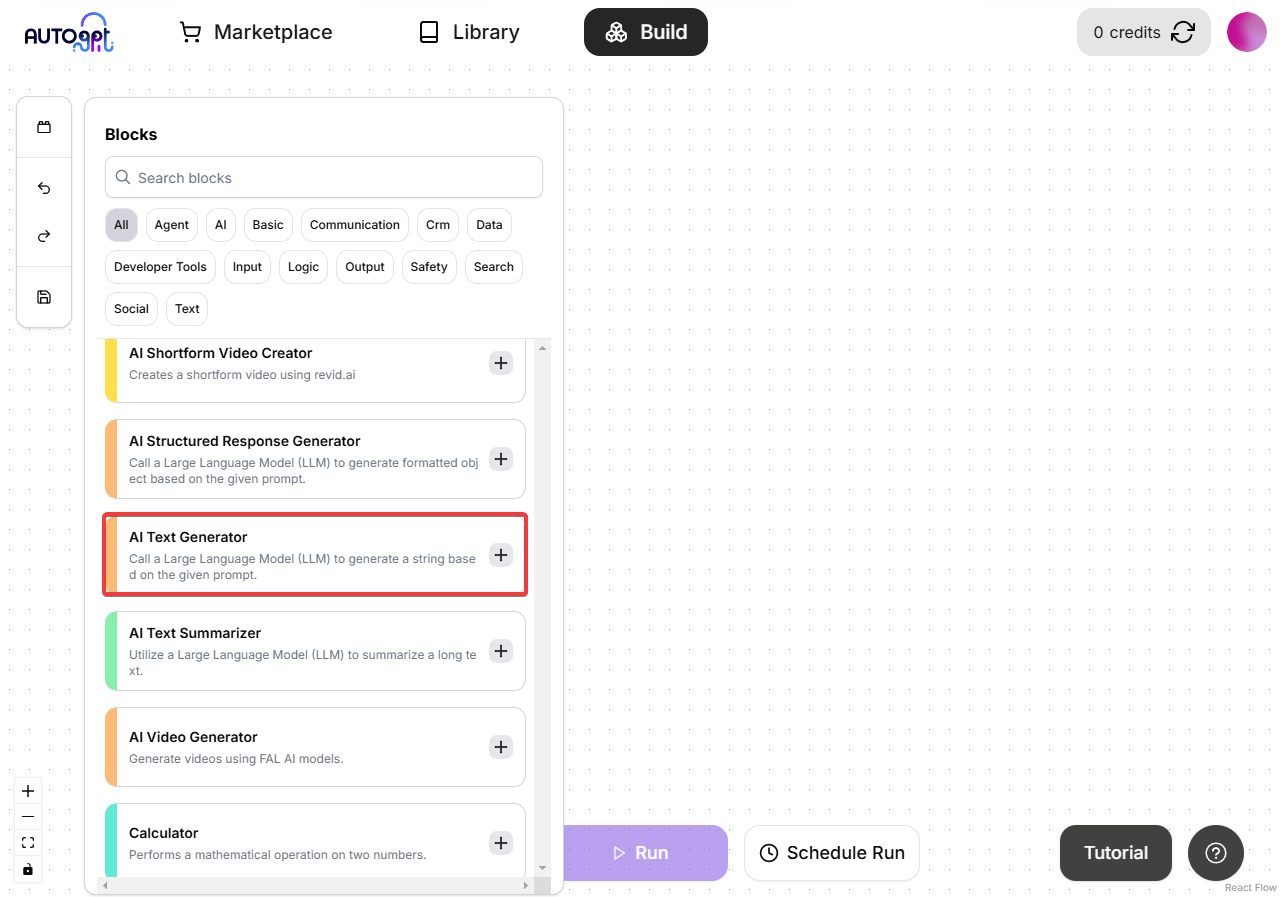
-
Configure the API Key field: Enter any value (e.g., "dummy" or "not-needed") since Ollama doesn't require authentication.
-
In the "LLM Model" dropdown, select "llama3.2" (This is the model we downloaded earlier)
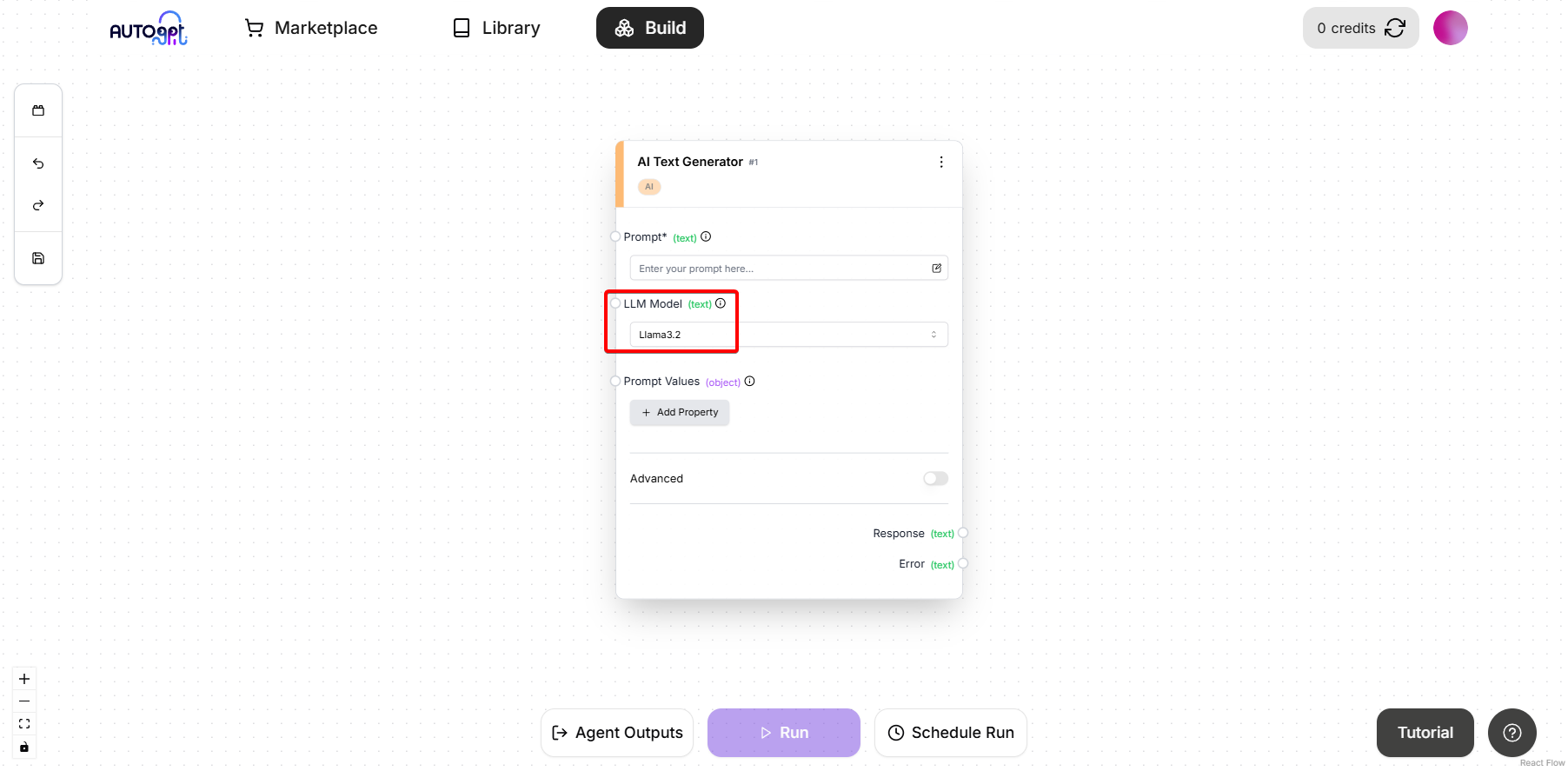
Compatible Models: The following Ollama models are available in AutoGPT by default: -
llama3.2(Recommended for most use cases) -llama3-llama3.1:405b-dolphin-mistral:latestNote: To use other models, follow the "Add Custom Models" step above.
- Set your local IP address in the "Ollama Host" field:
To find your local IP address:
Windows (Command Prompt):
ipconfig
Linux/macOS (Terminal):
ip addr show
ifconfig
Look for your IPv4 address (e.g., 192.168.0.39), then enter it with port 11434 in the "Ollama Host" field:
192.168.0.39:11434

Important: Since AutoGPT runs in Docker containers, you must use your host machine's IP address instead of
localhostor127.0.0.1. Docker containers cannot reachlocalhoston the host machine.
- Add prompts to your AI block, save the graph, and run it:
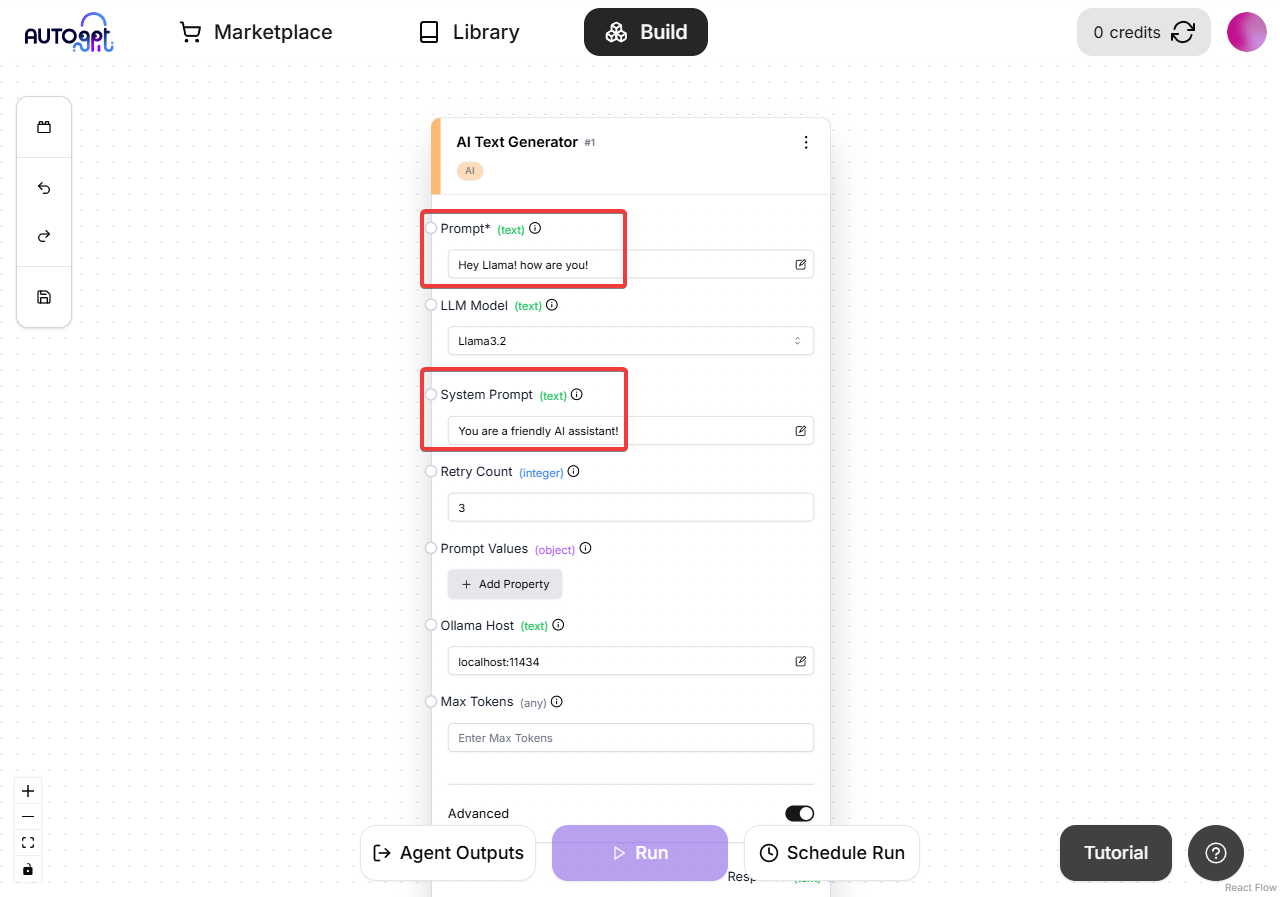
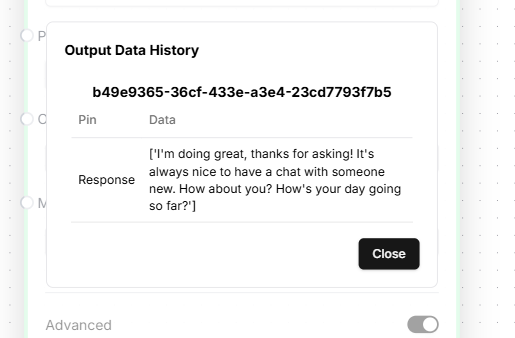
That's it! You've successfully setup the AutoGPT platform and made a LLM call to Ollama.
Using Ollama on a Remote Server with AutoGPT¶
For running Ollama on a remote server, simply make sure the Ollama server is running and is accessible from other devices on your network/remotely through the port 11434.
To find your local IP address of the system running Ollama:
Windows (Command Prompt):
ipconfig
Linux/macOS (Terminal):
ip addr show
ifconfig
Look for your IPv4 address (e.g., 192.168.0.39).
Then you can use the same steps above but you need to add the Ollama server's IP address to the "Ollama Host" field in the block settings like so:
192.168.0.39:11434
Add Custom Models (Advanced)¶
If you want to use models other than the default ones, you'll need to add them to the model list. Follow these steps:
- Add the model to the LlmModel enum in
autogpt_platform/backend/backend/blocks/llm.py:
Find the Ollama models section (around line 119) and add your model like the other Ollama models:
# Ollama models
OLLAMA_LLAMA3_3 = "llama3.3"
OLLAMA_LLAMA3_2 = "llama3.2"
OLLAMA_YOUR_MODEL = "The-model-name-from-ollama" # Add your model here
- Add model metadata in the same file:
Find the MODEL_METADATA dictionary (around line 181) and add your model with its metadata:
# In MODEL_METADATA dictionary, add:
LlmModel.OLLAMA_YOUR_MODEL: ModelMetadata("ollama", 8192, None),
Where:
"ollama"= provider name8192= max context window (adjust based on your model)-
None= max output tokens (None means no specific limit) -
Add model cost configuration in
autogpt_platform/backend/backend/data/block_cost_config.py:
Find the MODEL_COST dictionary (around line 54) and add your model:
# In MODEL_COST dictionary, add:
LlmModel.OLLAMA_YOUR_MODEL: 1,
Note: Setting cost to
1is fine for local usage as cost tracking is disabled for self-hosted instances.
-
Rebuild the backend:
docker compose up -d --build -
Pull the model in Ollama:
ollama pull your-model-name
Troubleshooting¶
If you encounter any issues, verify that:
- Ollama is properly installed and running with
ollama serve - Docker is running before starting the platform
- If running Ollama outside Docker, ensure it's set to
0.0.0.0:11434for network access
Common Issues¶
Connection Refused / Cannot Connect to Ollama¶
- Most common cause: Using
localhostor127.0.0.1in the Ollama Host field - Solution: Use your host machine's IP address (e.g.,
192.168.0.39:11434) - Why: AutoGPT runs in Docker containers and cannot reach
localhoston the host - Find your IP: Use
ipconfig(Windows) orifconfig(Linux/macOS) - Test Ollama is running:
curl http://localhost:11434/api/tagsshould work from your host machine
Model Not Found¶
- Pull the model manually:
ollama pull llama3.2 - If using a custom model, ensure it's added to the model list in
backend/server/model.py
Docker Issues¶
- Ensure Docker daemon is running:
docker ps - Try rebuilding:
docker compose up -d --build
API Key Errors¶
- Remember that Ollama doesn't require authentication - any value works for the API key field
Model Selection Issues¶
- Look for models with "ollama" in their description in the dropdown
- Only the models listed in the "Compatible Models" section are guaranteed to work